Project
TiME: Tiny Monolingual Encoders for Efficient NLP Pipelines
December 2025
TLDR: TiME distills small, monolingual Transformer encoders (3 sizes across 16 languages) from large teachers like XLM-R-Large. The models retain 98% of teacher accuracy while being up to 5x faster and using 30x less energy per inference. Ideal for production NLP pipelines (NER, POS tagging, parsing) where speed, cost, and sustainability matter.
Overview
TiME is my master thesis project on training small, production friendly Transformer encoders for the kind of tasks that show up in real NLP pipelines. Think POS tagging, lemmatization, dependency parsing, NER, and a bit of extractive QA. The core idea is simple: instead of shipping a huge general model everywhere, distill task ready monolingual encoders that are fast, energy efficient, and still strong on benchmarks.
I distilled MiniLMv2 style students for 16 languages, with three student sizes per language, and evaluated them not only on accuracy but also on latency, throughput, and energy per sample.
The problem with big models in production
A lot of NLP infrastructure does not need a giant general purpose model. Many pipelines repeatedly run the same encoder on huge volumes of text, or need low latency responses. In those settings, model size turns into real cost: slower inference, higher GPU spend, and higher energy use.
Consider the typical workflow at a company processing millions of documents per day. Every document might go through named entity recognition, part of speech tagging, dependency parsing, and maybe some form of information extraction. If you are running XLM-R-Large for each of these steps, you are looking at a 560M parameter model that processes around 370 sentences per second at optimal batch size. That sounds fast until you multiply it by the volume of text and realize your GPU costs are climbing rapidly.
The problem gets worse when latency matters. Interactive applications like search, real time document analysis, or retrieval preprocessing cannot afford to wait 11 milliseconds per inference. Users notice delays above 100ms, and when you are chaining multiple NLP steps together, those milliseconds add up quickly.
And then there is energy. A single inference on XLM-R-Large consumes about 0.82 Joules. That might sound tiny, but at scale it translates into significant electricity bills and carbon footprints. For companies with sustainability commitments, this is increasingly a real constraint.
All speed and energy numbers in this post are measured on an NVIDIA A100 and are averaged across the seven core languages unless stated otherwise.
TiME targets exactly this gap: small encoders that you can actually deploy at scale without wasting compute and energy.
What I built
The work is a complete distillation and evaluation pipeline, centered around three parts.
Distillation with MiniLMv2 attention relation transfer, so the student learns the internal attention structure of a strong teacher instead of only copying final logits. The key insight from MiniLMv2 is that self-attention relations, the scaled dot products between query, key, and value vectors, capture rich structural information about how the model processes language. By training the student to mimic these relations, we transfer more nuanced knowledge than simple output matching would provide.
Checkpoint selection that does not rely on downstream task labels: pick the best checkpoint via distillation loss on external validation text, with special care for low resource languages. This matters because the conventional approach of evaluating on downstream tasks during pre-training is expensive and sometimes impossible for languages without labeled data.
Downstream evaluation and efficiency benchmarking across multiple tasks, plus explicit speed and energy measurements. Most papers only report accuracy. I wanted to know: if I deploy this model, what will it actually cost me?
Teachers, students, and the mismatch that mattered
I distilled from two types of teachers.
First, a strong multilingual teacher: XLM-R-Large. This is the 560M parameter multilingual model from Meta that covers over 100 languages. It is arguably the strongest publicly available multilingual encoder, which makes it an ideal knowledge source.
Second, strong monolingual teachers from HPLT, which use the LTG BERT architecture. LTG BERT uses relative position embeddings and other architectural tweaks like GeGLU activations. The HPLT models are specialized for individual languages and often outperform multilingual models on their target language.
Here is where it gets interesting: the students I distilled are standard BERT style encoders with absolute position embeddings. I wanted the students to be compatible with common tooling, even if that meant distilling across an architectural mismatch. Most NLP libraries expect standard BERT architecture. Using relative position embeddings or GeGLU activations would require users to modify their inference code, which defeats the purpose of creating drop-in replacements.
The MiniLMv2 distillation method turned out to be robust enough to bridge these differences. Knowledge transferred successfully despite the change in position embedding strategy and activation functions. This was not guaranteed to work, and it is one of the more surprising findings of the project.
For the students, I used three sizes:
| Size | Layers | Hidden Size | Use Case |
|---|---|---|---|
| m (medium) | 6 | 768 | Best accuracy, still fast |
| s (small) | 6 | 384 | Balanced trade-off |
| xs (extra-small) | 4 | 384 | Maximum speed |
This gives a practical range from “still pretty accurate” to “as fast as possible”. The medium models retain most of the teacher quality. The extra-small models push efficiency as far as it can go while still being useful.
Training and checkpoint selection
Each training run saved 20 checkpoints across 200k steps. Instead of guessing which one will fine tune best later, I selected checkpoints by measuring the distillation loss on an external validation set that the model never sees during distillation.
For Irish, validation used FLORES-200 dev. For the other languages, validation used the appropriate side of WMT24++ parallel data. The point was to bias towards checkpoints that generalize, especially where the distillation data is small and overfitting is a real risk.
Why does this matter? For low resource languages, the amount of unique training text might only cover a few epochs worth of training. Extended training in this setting leads to overfitting: the model memorizes the training data rather than learning generalizable patterns. By validating on external text, we catch this before it becomes a problem.
The approach is also practical. It does not require any labeled data for the target language, which means you can apply it to languages that lack annotated corpora for standard NLP tasks.
What I measured, and how
Accuracy alone is not enough if the goal is deployment. So the evaluation tracked two kinds of outcomes.
First, standard downstream task performance: NER, POS tagging, lemmatization, dependency parsing, plus MLQA extractive QA for English and German. These are the tasks that real NLP pipelines actually run. I used Universal Dependencies treebanks and WikiAnn for evaluation, following the same setup as the original HPLT evaluation.
Second, efficiency metrics that reflect real inference cost:
Latency at batch size 1. This is what matters for interactive applications where you cannot batch requests together. If a user sends a query, you need to respond quickly.
Throughput at the optimal batch size per model. This is what matters for batch processing pipelines. Given a queue of documents, how fast can you process them?
Energy per sample by sampling GPU power draw via nvidia-smi during inference and converting to Joules per processed sample. This is often overlooked, but energy cost is becoming increasingly important for both economic and environmental reasons.
All speed benchmarks ran on an NVIDIA A100-SXM4-80GB GPU with 110 batches of 32 sentences, using 10 batches for warmup.
Results: where TiME lands on the efficiency frontier
The distilled TiME models land on the practical performance efficiency frontier: they preserve most of the teacher quality on common NLP tasks while being much cheaper to run.
Here is the summary across seven core languages (English, German, French, Danish, Hungarian, Urdu, Irish):
| Model | Avg Score | Latency Speedup | Throughput Speedup | Energy Improvement |
|---|---|---|---|---|
| XLM-R-Large | 89.2 | 1.0x | 1.0x | 1.0x |
| XLM-R-Base | 87.9 | 1.9x | 3.2x | 3.3x |
| TiME-m | 87.7 | 3.9x | 5.4x | 6.6x |
| TiME-s | 85.2 | 3.9x | 15.9x | 18.7x |
| TiME-xs | 83.9 | 5.8x | 25.2x | 30.2x |
| mMiniLM | 83.5 | 3.5x | 16.9x | 19.4x |
The TiME-m models retain 98.4% of the XLM-R-Large teacher score while being nearly 4x faster and using about 6x less energy per sample. The TiME-xs models push to 25x throughput improvement and 30x energy improvement, trading about 5 points of accuracy for massive efficiency gains.
Compared to the existing mMiniLM baseline (a multilingual distilled model), our TiME models consistently perform better across all languages while achieving similar or better efficiency. This is because monolingual distillation can focus the model capacity on a single language rather than spreading it across 100+.
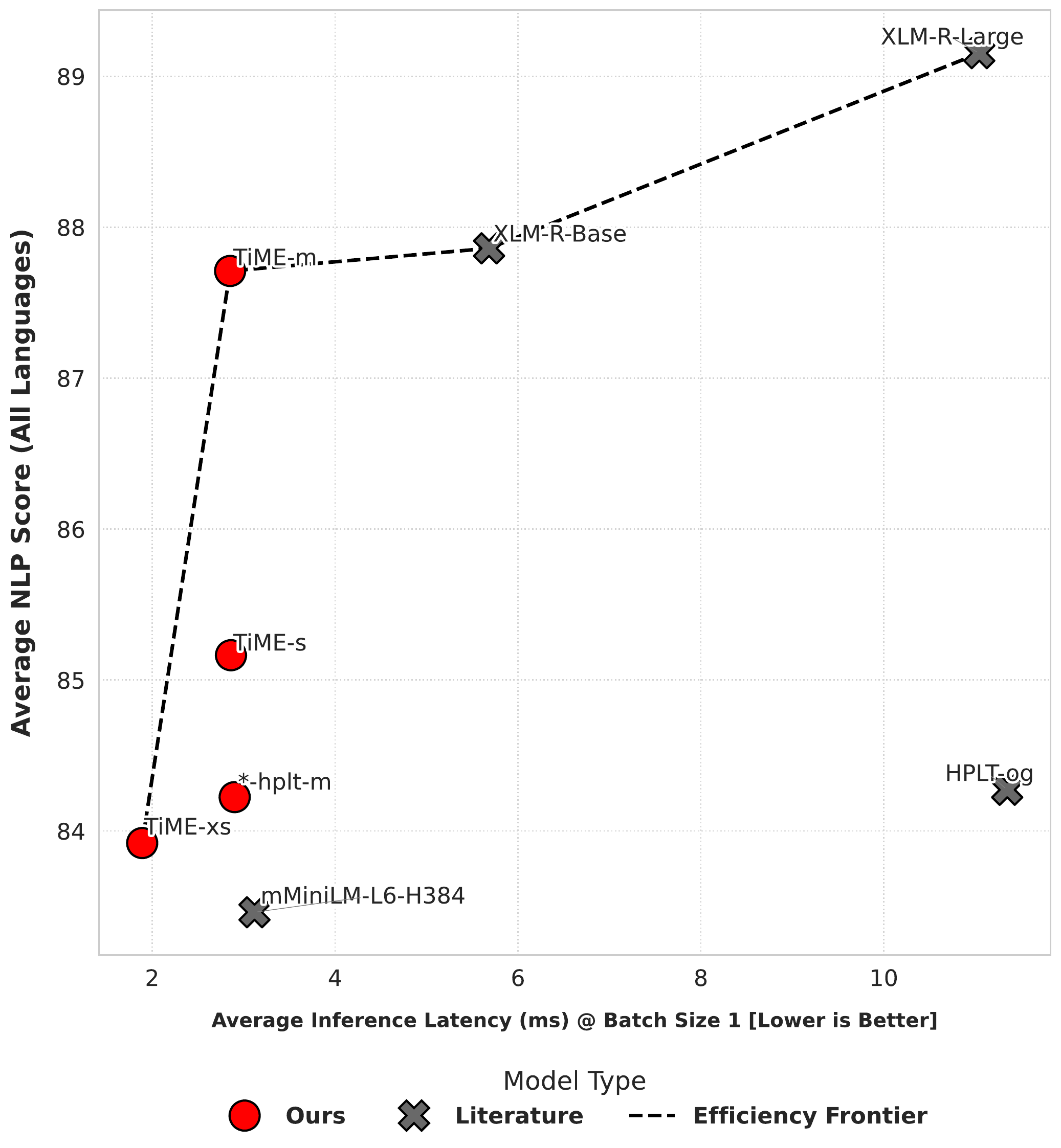 Performance vs latency, averaged across languages. TiME models (red) sit on the efficiency frontier.
Performance vs latency, averaged across languages. TiME models (red) sit on the efficiency frontier.
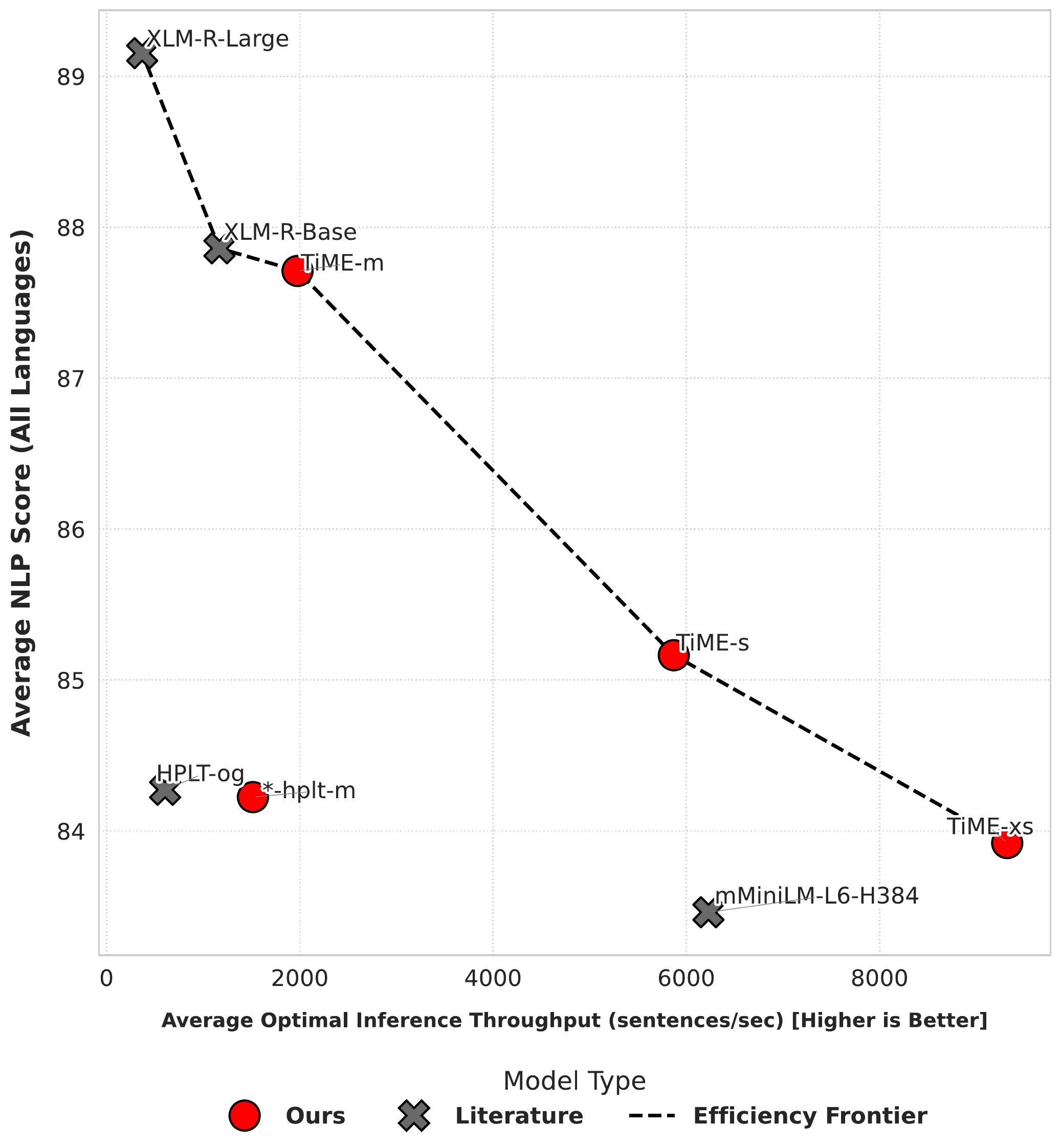 Performance vs throughput at each model’s optimal batch size. Note the log scale on throughput.
Performance vs throughput at each model’s optimal batch size. Note the log scale on throughput.
The energy story
One finding that surprised me was how much the efficiency gains compound when you look at energy consumption. Speed improvements do not translate linearly to energy savings because smaller models also draw less power at any given batch size.
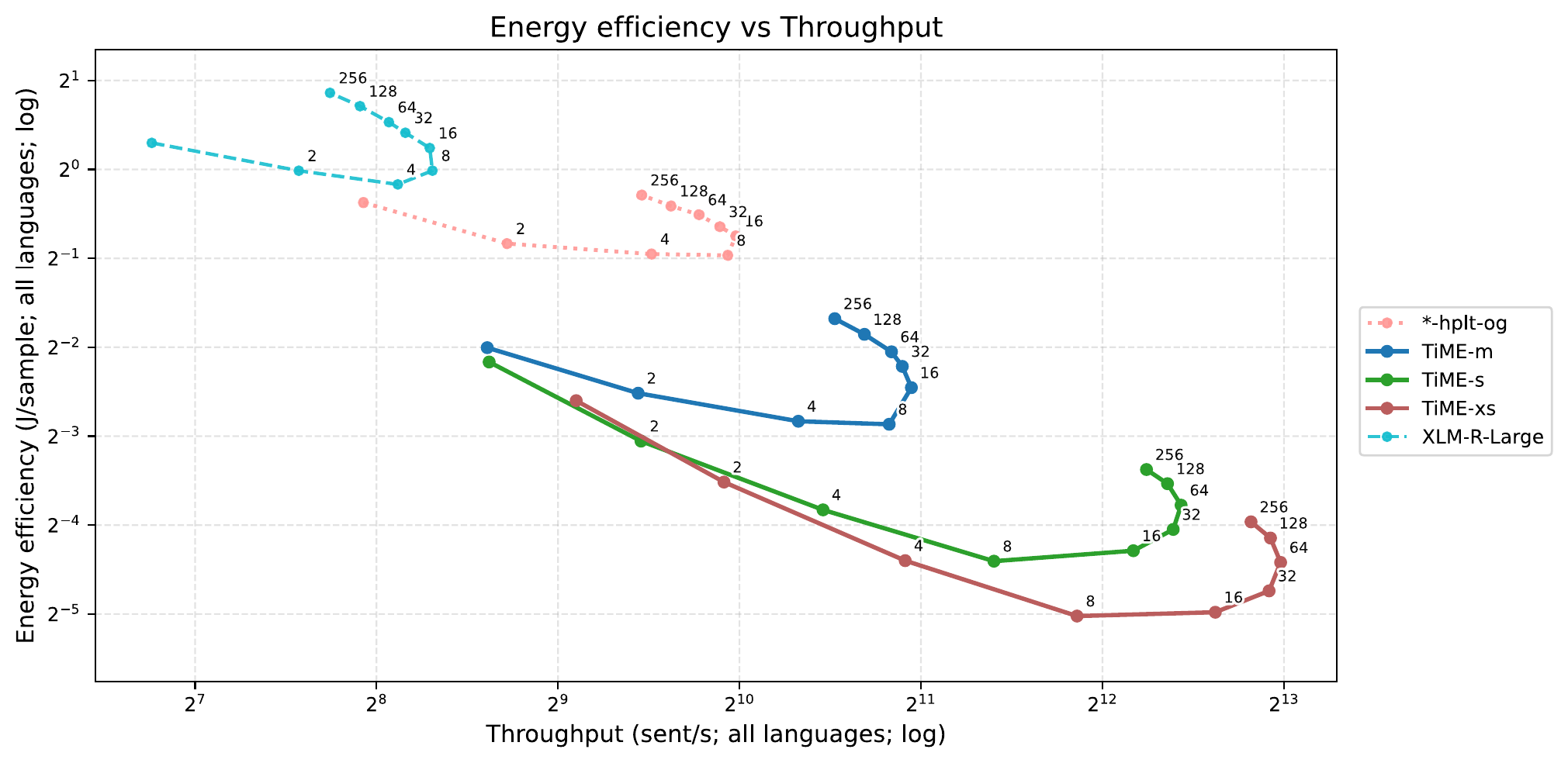 Energy per sample vs throughput across batch sizes. Smaller models reach lower energy floors.
Energy per sample vs throughput across batch sizes. Smaller models reach lower energy floors.
The TiME-xs models achieve around 0.02-0.03 Joules per sample at optimal batch size, compared to 0.82 Joules for XLM-R-Large. That is roughly 30x less energy per inference. At scale, this difference becomes substantial.
There is also an interesting U-shaped pattern within each model family. As batch size increases, energy per sample falls (because fixed costs are amortized over more samples) until a saturation point. Beyond that, pushing for the last bit of throughput actually increases energy per sample again. This suggests there is an optimal operating point that balances throughput and energy efficiency, typically at moderate batch sizes around 8-16.
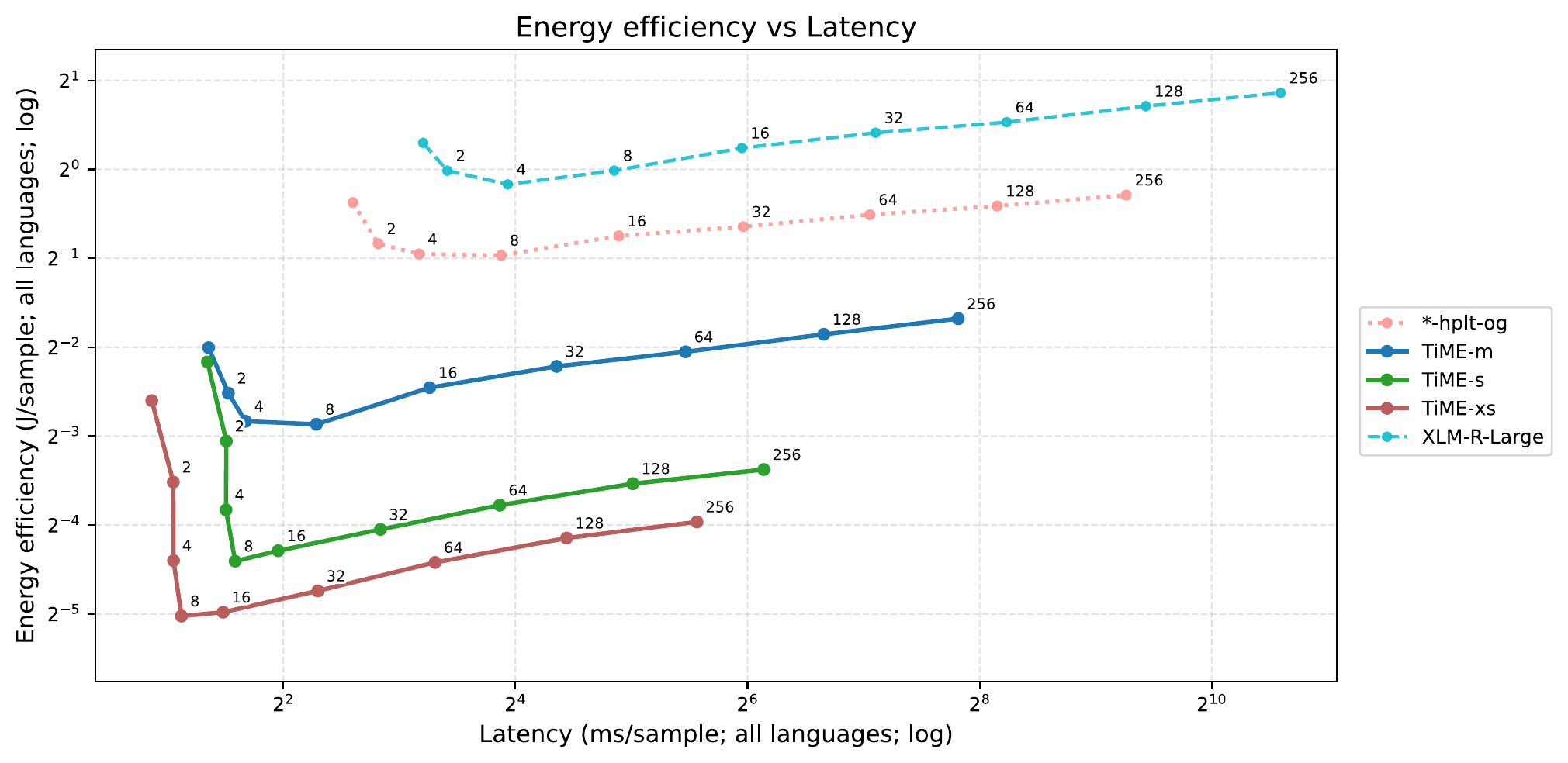 Energy per sample vs latency across batch sizes.
Energy per sample vs latency across batch sizes.
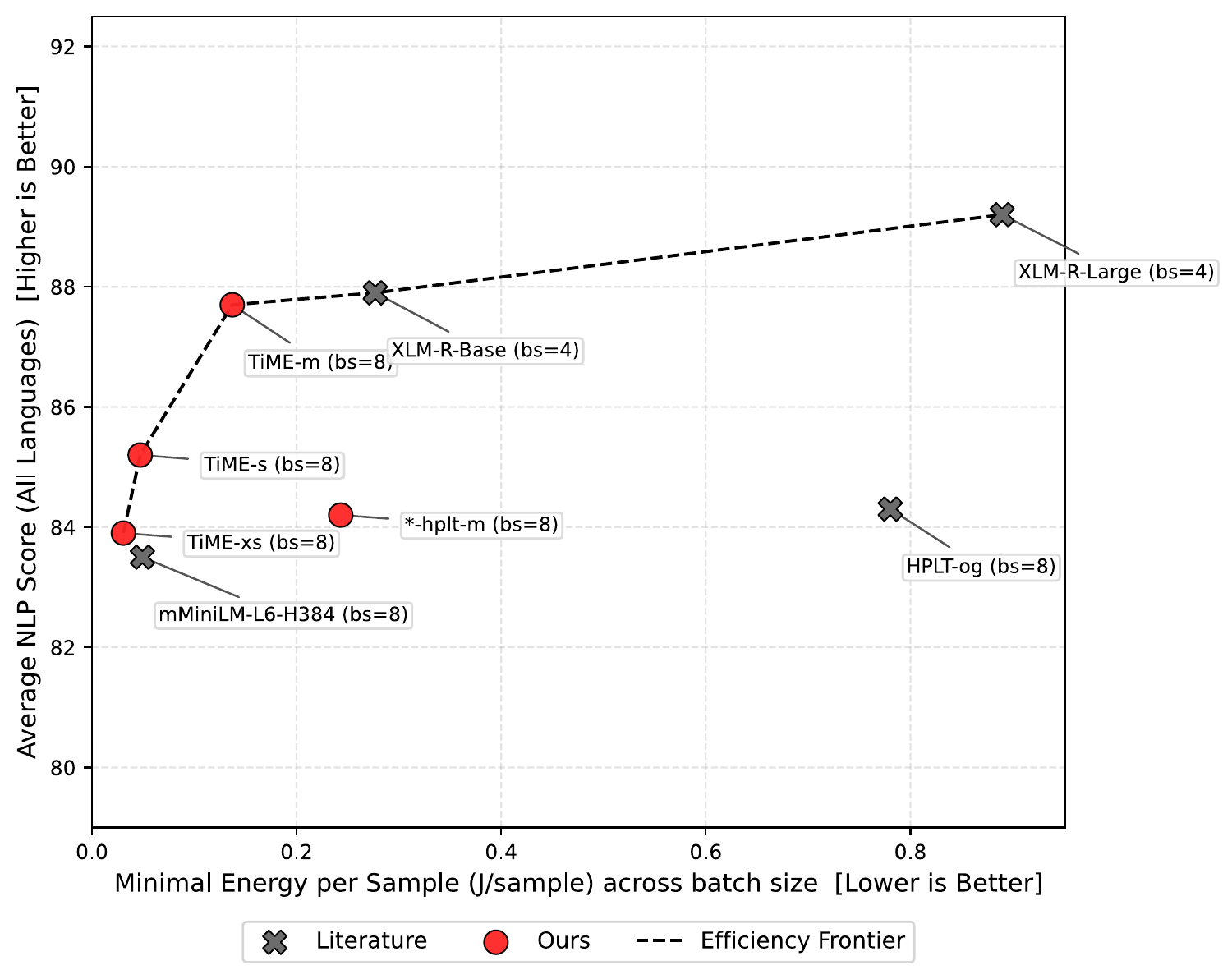 NLP score vs minimal energy per sample, showing the Pareto frontier.
NLP score vs minimal energy per sample, showing the Pareto frontier.
Low resource languages: Irish and Hungarian
One of the motivations for this project was to support languages that are often underserved by existing NLP tooling. Irish (ga) is a genuinely low resource language with limited training data. Hungarian (hu) is morphologically complex, which makes it challenging for compression.
The results show that TiME models work well even in these harder settings:
| Language | TiME-m Score | XLM-R-Large Score | Retention |
|---|---|---|---|
| Irish | 82.4 | 83.1 | 99.2% |
| Hungarian | 80.8 | 81.6 | 99.0% |
| English | 91.1 | 92.4 | 98.6% |
| German | 88.4 | 90.5 | 97.7% |
For Irish, the TiME-m model closes to within 0.7 points of the teacher. For Hungarian, it is within 0.8 points. These are both cases where we might expect compression to struggle, but the distillation pipeline handles them gracefully.
The checkpoint selection mechanism helps here. By validating on external text (FLORES-200 for Irish, WMT24++ for others), we avoid overfitting even when the distillation corpus is small.
Question answering: does it generalize beyond NLP tasks?
The core NLP tasks (tagging, parsing, NER) are somewhat similar to each other. They all involve sequence labeling or dependency prediction. To test whether the distilled models retain more general language understanding, I evaluated on MLQA, an extractive question answering benchmark.
| Model | English F1 | English EM | German F1 | German EM |
|---|---|---|---|---|
| TiME-xs | 70.0 | 56.2 | 50.3 | 33.7 |
| TiME-s | 75.1 | 61.5 | 56.7 | 39.1 |
| TiME-m | 81.2 | 67.7 | 61.1 | 42.3 |
| XLM-R-Base | 81.3 | 67.9 | 60.0 | 42.0 |
| XLM-R-Large | 84.3 | 71.1 | 65.8 | 45.9 |
The TiME-m models match or exceed XLM-R-Base on QA while being smaller and faster. They close much of the gap to XLM-R-Large, suggesting that the distillation preserves general language understanding, not just task-specific features.
Comparison with spaCy
To put these results in context, I compared against spaCy’s transformer pipelines, which are the standard production NLP toolkit. SpaCy uses established encoders like RoBERTa (English), German BERT, CamemBERT (French), and DanskBERT (Danish).
| Language | Model | Avg Score | Latency (ms) | Throughput (s/s) |
|---|---|---|---|---|
| English | TiME-m | 91.1 | 2.9 | 1539 |
| English | TiME-xs | 87.6 | 1.9 | 6362 |
| English | spaCy trf | 91.3 | 5.1 | 1330 |
| German | TiME-m | 88.4 | 2.9 | 3471 |
| German | TiME-xs | 84.8 | 1.9 | 10652 |
| German | spaCy trf | 89.2 | 4.9 | 2046 |
| French | TiME-m | 93.2 | 2.9 | 1454 |
| French | TiME-xs | 91.1 | 1.9 | 5077 |
| French | spaCy trf | 93.1 | 5.1 | 1271 |
The TiME-m models match spaCy’s accuracy and are up to about 1.7x faster on throughput in the cases shown here, with substantially lower latency. The TiME-xs models are about 4-5x faster with only modest accuracy loss. For high volume applications, this translates directly to cost savings.
The throughput-latency trade-off
One non-obvious finding is how batch size affects the throughput-latency trade-off differently for different model sizes.
 Latency vs throughput as batch size changes. Smaller models reach their efficiency plateau at lower batch sizes.
Latency vs throughput as batch size changes. Smaller models reach their efficiency plateau at lower batch sizes.
Larger models need bigger batches to fully utilize the GPU. Smaller models reach their efficiency plateau at lower batch sizes. This matters for deployment: if you cannot guarantee large batches (because requests arrive sporadically), smaller models give you better efficiency at the operating points you actually use.
Limitations and what comes next
This work has some clear limitations that point toward future directions.
Architectural choices were hand-picked. I chose three sizes (m, s, xs) based on intuition about practical operating points. A more systematic architectural search could find Pareto optimal configurations that I missed. Neural architecture search for distillation targets is an interesting research direction.
Domain coverage is limited. The evaluation uses news and Wikipedia style text. Performance on social media, legal documents, scientific papers, or other domains might differ. Domain-specific evaluation would stress test robustness.
QA evaluation is limited to English and German. MLQA only covers those two languages from my core set. Expanding to other multilingual QA datasets would give a fuller picture of how well the distillation preserves general language understanding.
Single-run evaluation. For computational reasons, all results come from single training and fine-tuning runs. Variance across seeds is unknown. The scores should be interpreted as strong indicators rather than exact reproducible numbers.
If I were to extend this work, I would focus on three things:
-
Pareto optimal architecture search. Instead of picking sizes by hand, use multi-objective optimization to find architectures that maximize accuracy while minimizing latency and energy.
-
Domain robustness. Evaluate on a wider range of text types to understand where the compressed models break down.
-
Extreme low resource. Push to even lower resource languages and understand the minimum data requirements for effective distillation.
Conclusion
TiME shows that you can have fast, efficient NLP without giving up much accuracy. The recipe is straightforward: distill from a strong teacher using MiniLMv2’s attention relation transfer, select checkpoints by validation loss on external text, and evaluate on both accuracy and efficiency.
The resulting models sit on the Pareto frontier of performance vs cost. For production NLP pipelines that process large volumes of text or need low latency, they offer a practical alternative to shipping giant multilingual models everywhere.
The efficiency gains compound: 5x faster, 30x less energy, same quality of results. At scale, that translates to real savings in compute costs and carbon footprint.
Links
Code: GitHub
Models: Hugging Face collection
Paper: arXiv